Managing cloud infrastructure often involves the creation and management of many components: subnet IP ranges, databases, clusters, file storage, access control policies and more.
At the application layer, we use many repeated, common objects. These might include hardened OS images, Docker images, or pre-defined and approved configuration files that ensure adherence to security standards. These infrastructure components and elements can be found in almost all cloud architectures.
It therefore makes sense to view these components as repetitive or reusable. Imagine the control and flexibility of being able to package both infrastructure and configuration into a descriptive format. Then, imagine storing those definitions in a centralized, version controlled repository. Finally, picture the possibility of allowing multiple teams, projects, or services to deploy those trusted components quickly and easily.
Terraform templates provide exactly this, by packaging cloud infrastructure components and application configurations into infrastructure as code (IaC). This facilitates the quick, repeatable, validated deployment of services into any cloud.
In this article we will describe the two main functions of Terraform templates:
- Infrastructure modularization – by using Terraform Modules
- Configuration templatization – by using Terraform’s templatefile() function
Before we continue, it may be useful to provide a breakdown of common Terraform terminology, which we will use throughout the article.
| Concept | Description |
|---|---|
| modules | collections of Terraform files, including IO variables and resources that are to be created |
| child module | when modules are called from parent Terraform code, they are referred to as child modules |
| input/output | Terraform files define input variables, default values and output values used by the parent code |
| resources | usually defined in the main.tf file within the module – it is responsible for creating a set of cloud resources |
| templatefile() | uses the file path as a parameter to create configuration files on the target system. The file itself is dynamic – replacement of variables happens at runtime |
| file provisioners | a type of provisioner used to copy files from a Terraform host to a target VM) |
| jsonencode, yamlencode | encoding functions offered by Terraform to convert strings to JSON or YAML format |
| user_data | Bash script that runs when an AWS EC2 instance boots |
Terraform templates and modules
Terraform Modules enable us to organize cloud infrastructure components into logical containers. It is a grouping of configuration files that together describe a specific action or task. We could refer to these logical groupings as “contexts” and various teams could use them to organize and deploy cloud infrastructure quickly and predictably. Below is a list of contexts that Terraform Modules might be tied to:
- Network components – IaC to provision generic networking components with scope for further customization.
- Storage components – IaC that provisions databases along with configurations relating to backups, availability, encryption and so on
- IAM policies – IaC that manages permissions associated with access to infrastructure objects
- Compute components – IaC that creates VMs, clusters, containers, host workloads, admin access gateways, web servers and so on.
The development and definition of modules allows teams to provide inputs in the form of “input variables”. These can help teams align cloud infrastructure with their specific requirements, without changing the source code of the module itself.
Similarly, when configuring compute nodes, Terraform’s templatefile() function helps create predefined configuration files based on input parameters. Typically, web servers, operating systems, network devices, applications and so on, are configured differently for different situations. Configuration files expose parameters within these resources that allow administrators to alter their behavior and are specific to each resource.
Configuration files come in different formats and syntaxes. Configuration files can be used for proxy settings, web server configs, network configs, application-specific configs and so on.
templatefile() (*.tftpl) functions, along with user_data (in the case of AWS EC2) help us define appropriate functions for a given compute node. The contents of a configuration file could be text, JSON, or YAML. Additionally, critical variations in configuration are also managed using templatefile().
Terraform templates in action
We will now step through a practical example. Web application servers are used in most cloud deployments and organizations typically set a standard baseline for them. In our example, we will do the same:
- all web servers should use an Ubuntu 20.04 image
- the size used will be: t2.micro
- the number of web servers to be created should be flexible
- we will set the nameservers in the resolv.conf file with specified values
- we will install Nginx

Customizable guardrails to embed FinOps policies into new workload provisioning

Self-service catalogs to provision compliant, cost-efficient resources in private and public clouds

Accountable FinOps workflows with task assignment, chargeback reports, and scorecards
Modules
Modules are used to create infrastructure templates in Terraform and consist mainly of 3 files:
- main.tf – defines the resources to be created
- variables.tf – defines the input variables needed by the main.tf file
- output.tf – defines the list of output for the created infrastructure
Our infrastructure baseline requires us to standardize a few parameters and provide flexibility in the number of servers we can deploy. We will therefore create a Terraform Module that satisfies this requirement. Our example main.tf file below, specifies the image and type, along with the count attribute. We have intentionally used the least number of variables for the sake of simplicity.
//EC2 Instances
resource "aws_instance" "my_web_servers" {
ami = "ami-0d527b8c289b4af7f" //Ubuntu 20.04
instance_type = "t2.micro"
count = var.vm_count
}
Inputs/Outputs
We have used one input variable “vm_count” that defines the number of EC2 instances to be created. We declare the variable(s) in a separate file – variables.tf.
variable "vm_count" {
type = number
default = 1
}
output.tf file asks Terraform to output all IP Addresses associated with the newly created web servers.
output "instance_ip_addr" {
value = aws_instance.my_web_servers[*].private_ip
}
As a final step, we copy these files into a directory, in this case named “webservers”. Ideally, this should be published to the central repository, so that the code can also be used by others to deploy web servers.
Reusing modules
The files above included a Terraform Module that created a number of EC2 instances, as per the count. By default, it creates a single EC2 instance. To use this module in a project that requires web servers, we can use the “module” block as below.
module "my_web_servers" {
source = "./webservers"
vm_count = 5
}
output "ws_ips" {
value = module.my_web_servers.instance_ip_addr
}
Here we are using the “webservers” module locally in a “TFTEMPLATE” Terraform code directory. Thus, the source attribute contains the path to this directory. We have also supplied a value of 5 to the vm_count variable, required by the child module.
To display the output generated by the child module “webservers”, we have created an output variable “ws_ips” to display the output at the end of provisioning. The output variable in the parent module refers to the “instance_ip_addr” output of the child module.
The final directory structure should look something like the below.
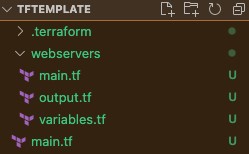
Here, “webservers” is a child module being used by the “tftemplate” Terraform code.
Resources
The Main.tf file in the child module – webservers – defines the resources that will be created after applying the Terraform code. If we add more resources to the webservers module, the same is reflected in all projects where the module is used.
Running “terraform plan” successfully produces the below output.
Plan: 5 to add, 0 to change, 0 to destroy.
Changes to Outputs:
Plan: 5 to add, 0 to change, 0 to destroy.
Changes to Outputs:
+ ws_ips = [
+ (known after apply),
+ (known after apply),
+ (known after apply),
+ (known after apply),
+ (known after apply),
]
The Terraform code in the “TFTEMPLATE” directory may contain additional components and child modules, that create additional resources specific to the infrastructure.
File provisioners
At the infrastructure level, we have successfully created an infrastructure “template” in the form of a “webservers” module. However, a few requirements in the baseline have yet to be fulfilled. These requirements are at the application layer:
- installation of an Nginx web server
- setting the nameservers in the resolv.conf file
We shall address setting the nameservers first. A resolv.conf file should reside on a target path available to the newly provisioned EC2 instance. We will make use of Terraform File Provisioners within the “aws_instance” block to achieve this.
File Provisioners copy a source file, from a specified path on a Terraform host (where Terraform executes), to the destination path on a target VM.
Since this is a baseline requirement, it needs to be part of the template/module. We will create/copy the actual resolv.conf file within the “webservers” child module as below:
nameserver 192.168.0.1 nameserver 8.8.8.8 nameserver 8.8.4.4
This results in the following new directory structure:
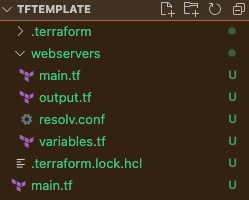
Here we add the file provisioner to the aws_instance in the “./webservers/main.tf” file.
//EC2 Instances
resource "aws_instance" "my_web_servers" {
ami = "ami-0d527b8c289b4af7f" //Ubuntu 20.04
instance_type = "t2.micro"
count = var.vm_count
provisioner "file" {
source = "./resolv.conf"
destination = "/etc/resolv.conf"
}
}
Template File and For Loop
The resolv.conf file is fairly straightforward. It is repetitive in nature and contains unique IP address values. As per our baseline requirement, IP address values for DNS resolution should be kept dynamic.
In our case, these values are essentially hardcoded, since we are simply copying and pasting the file in the target destination. Instead of using this file, we could use a Terraform template file (*.tftpl) and make it more dynamic by using a for loop. We will begin by renaming the resolv.conf file to resolv.conf.tftpl.
%{ for ip in ip_addrs ~}
nameserver ${ip}
%{ endfor ~}
The code above expects a list of “ip_addrs” and creates a .conf file with all the nameservers. We will supply the list of ip addresses via the templatefile() function and modify the “aws_instance” code block as shown below:
//EC2 Instances
resource "aws_instance" "my_web_servers" {
ami = "ami-0d527b8c289b4af7f" //Ubuntu 20.04
instance_type = "t2.micro"
count = var.vm_count
provisioner "file" {
source = templatefile("${path.module}/resolv.conf.tftpl", { ip_addrs = var.ns_ips })
destination = "/etc/resolv.conf"
}
}
The source file is assigned the output of the templatefile() function. This takes the filename as the first parameter, and the list of ip_addrs as the second attribute.
Additionally, we will use a variable (ns_ips) to refer to the list of IP addresses. This will introduce a little more flexibility to the module. These values can now be configured from the parent module, as below (file ./main.tf).
module "my_web_servers" {
source = "./webservers"
vm_count = 5
ns_ips = ["192.168.0.1", "8.8.8.8", "8.8.4.4"]
}
output "ws_ips" {
value = module.my_web_servers.instance_ip_addr
}
Now, when the Terraform code is executed (via an apply), it will create five EC2 instances, with each instance having a resolv.conf file containing our provided nameserver IP addresses.
User Data (user_data)
So far, we have successfully used templates to accomplish repetitive tasks. We have used the count attribute to create as many EC2 instances as we need and have made use of both templatefile() and for loops to inject nameserver configurations.
To satisfy our final baseline – installing Nginx and setting basic configurations – we will need a bash script and file provisioner. These files have no specific structure, instead, the system or application validates the syntax natively.
We may continue to use variables within templatefile() functions, if we wish, to introduce flexibility. For example, setting specific values within the nginx.conf file during run time. Let’s look at an example nginx.conf file below.
server {
listen 80 default_server;
listen [::]:80 default_server;
root /var/www/html;
index index.html;
server_name _;
location / {
try_files $uri $uri/ =404;
}
location /api/ {
proxy_pass http://localhost:8080/;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}
This is a basic example of a typical Nginx config, that reverse-proxies the backend application API. We might be able to see several cases here where the flexibility of using parameters could be useful (but will not go into detail here).
In this example, we will replace the values for index and the API path, and create a template file – nginx.conf.tftpl. An example of this can be seen below. This will allow other teams to provide their own specific path to the index.html and an API path to proxy any incoming requests.
server {
listen 80 default_server;
listen [::]:80 default_server;
root /var/www/html;
index ${index_file_path};
server_name _;
location / {
try_files $uri $uri/ =404;
}
location /${api_path}/ {
proxy_pass http://localhost:8080/;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}
Before we can use this config file however, we need to first install Nginx into our EC2 instances. We will create a simple bash script file (nginx.sh) below and use this in the user_data attribute.
sudo apt update sudo apt install nginx
Additionally, we will use the templatefile() function to execute the content of this file as user_data within the EC2 instances. Although there are no variables used in our current example, we could use them to run custom routines if we wished.
The final directory structure looks like below:
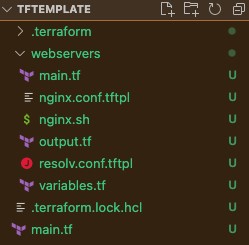
We will now modify the main.tf file of our child module to effect the following:
- To force the nginx.sh file to be supplied as user_data
- To use the nginx.conf.tftpl file to set basic Nginx configurations
//EC2 Instances
resource "aws_instance" "my_web_servers" {
ami = "ami-0d527b8c289b4af7f" //Ubuntu 20.04
instance_type = "t2.micro"
user_data = templatefile("nginx.sh")
count = var.vm_count
provisioner "file" {
source = templatefile("${path.module}/nginx.conf.tftpl", { index_file_path = var.nginx_file_path, api_path = var.nginx_api_path })
destination = "/etc/nginx/nginx.conf"
}
provisioner "file" {
source = templatefile("${path.module}/resolv.conf.tftpl", { ip_addrs = var.ns_ips })
destination = "/etc/resolv.conf"
}
}
The variable file now looks like the below. We have also set default values for cases where values are not supplied by the parent module.
variable "vm_count" {
type = number
default = 1
}
variable "ns_ips" {
type = list(string)
default = ["192.168.0.1", "8.8.8.8", "8.8.4.4"]
}
variable "nginx_file_path" {
type = string
default = "/var/www/html"
}
variable "nginx_api_path" {
type = string
default = "api"
}
If we run Terraform apply now, it will use the webservers module to:
- create five EC2 instances (Ubuntu 20.04 / t2.micro)
- set nameservers as per the list of IP addresses in the resolv.conf file
- install Nginx
- configure file and api paths
We have just successfully used Terraform Templates to create a reusable Terraform package!
Recommendations
Templating is a powerful way to speed up infrastructure design and deployment, with in-built conformity that matches your needs and standards. Reusability is a huge benefit, particularly as the packages will include many best practices and lessons learned from previous endeavors.
It’s true that Terraform templates may impose restrictions on infrastructure developers, but those same Devs will no longer have to worry about things like implementing security policies and standards themselves. The key is finding the right balance between security and developer freedom that satisfies as many use cases as possible. When building infrastructure templates, developers should generally be trusted with an appropriate level of flexibility and freedom.
Here are some other best practices:
- Strict template versioning should always be enforced to avoid introducing any unchecked and potentially damaging changes into newer versions.
- Use both jsonencode and yamlencode functions to generate config files that require valid JSON or YAML syntax.
- Templating is complex, so make sure to understand how string literals are used.
- When creating a template repository, standardize file names so that your teams can easily understand the code by convention.
- Before undertaking huge development tasks, check if similar modules already exist on the Terraform registry.
Featuring guest presenter Tracy Woo, Principal Analyst at Forrester Research
Conclusion
Cloud infrastructure is ubiquitous and Terraform is a great tool that can help manage, deploy and unify your resources in these complex environments. It can fall victim to the same code duplication problems that plague other development languages however, so use it wisely and follow the best practices we have listed above. Ultimately, Terraform templating can help keep your infrastructure code clean and reusable, so it’s worth considering if you are not already onboard. If you enjoyed this article and want to learn more, please check out some of our other Terraform chapters!
Related Blogs

The New FinOps Paradigm: Maximizing Cloud ROI
Featuring guest presenter Tracy Woo, Principal Analyst at Forrester Research In a world where 98% of enterprises are embracing FinOps,…

Ready to Run Webinar: Achieving Automation Maturity in FinOps
Automation has become essential to keeping up with today’s fast-paced cloud environment. Manual FinOps processes create bottlenecks, delay decisions, and…

