Kubernetes has become an essential component of modern cloud infrastructure, with adoption growing rapidly across industries. Recognized as the second-fastest-growing open-source project after Linux, the Kubernetes market is projected to expand at a 23.4% compound annual growth rate, reaching $9.7 billion by 2031.
Its scalability, resilience, and versatility make it a cornerstone of modern cloud infrastructure, attracting contributions from over 7,500 companies across various industries. However, as Kubernetes environments grow, so do challenges like resource inefficiencies, escalating costs, and operational complexities.
This guide explores six essential strategies for Kubernetes cost optimization. Alongside these best practices, we’ll uncover how Augmented FinOps transforms Kubernetes cost management through AI, automation, and real-time insights.
What is Kubernetes cost optimization?
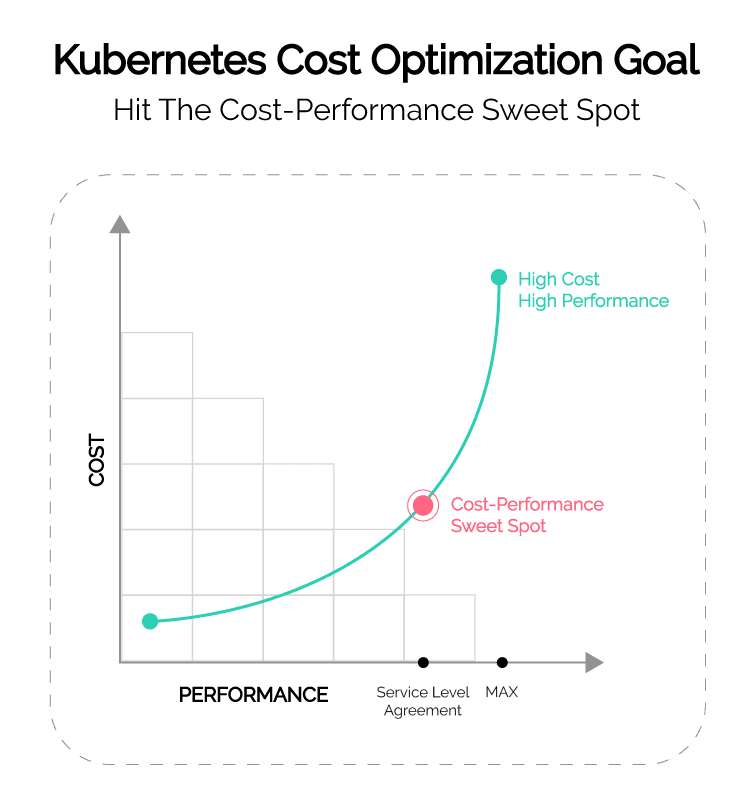
Kubernetes cost optimization involves fine-tuning cluster resources to minimize waste while maintaining—or even improving—performance. This includes optimizing pod scheduling, autoscaling strategies, storage provisioning, and network traffic management to align infrastructure efficiency with financial goals.
While Kubernetes offers flexibility and scalability, inefficiencies such as oversized nodes, underutilized workloads, and excessive storage provisioning often lead to inflated costs. Implementing a Kubernetes cost optimization strategy helps organizations harness Kubernetes’ full potential without overspending.
Key drivers of Kubernetes cost
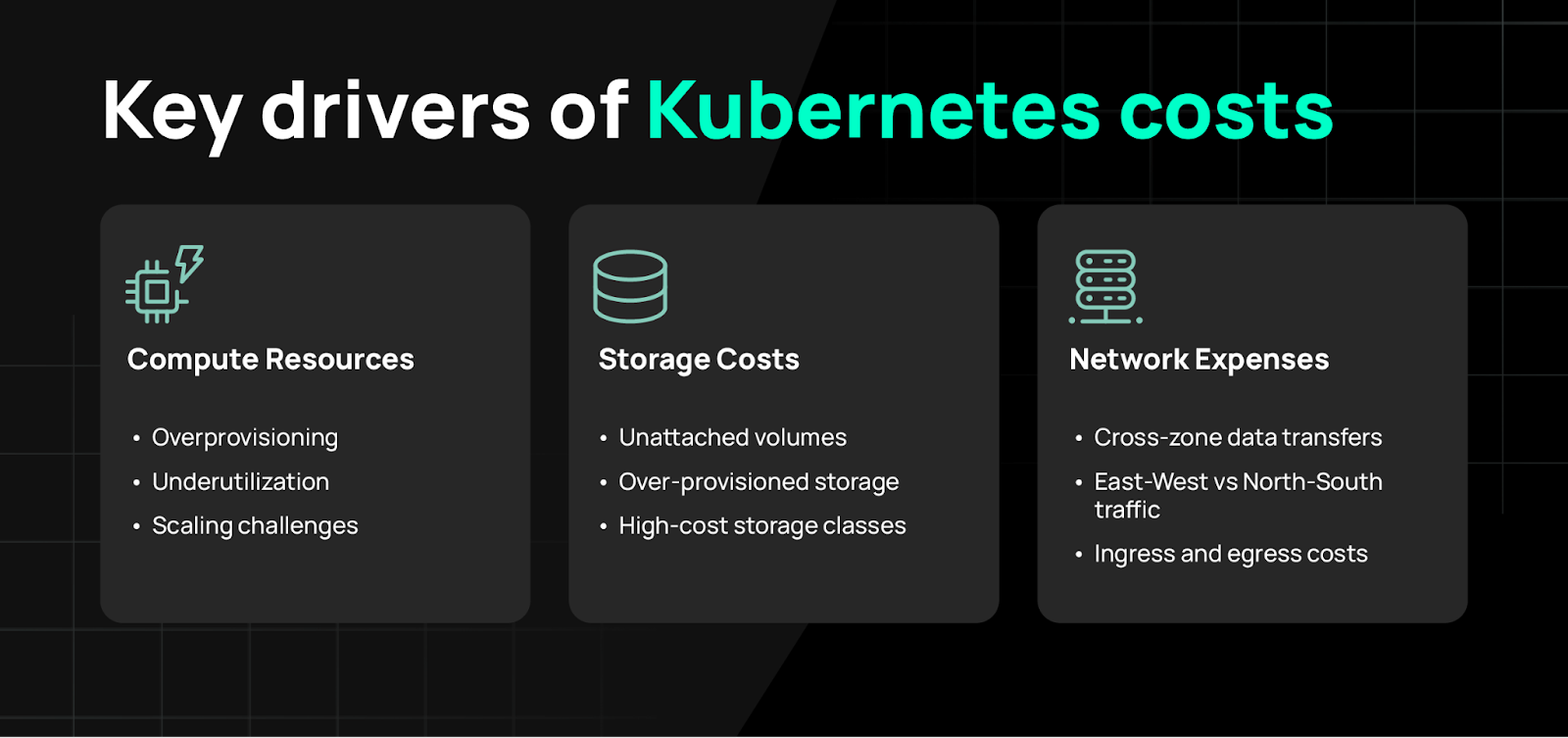
Compute resources
Kubernetes relies on cloud instances (e.g., AWS EC2, Azure VMs, Google Compute Engine) or on-premises servers to deliver the processing power needed to run workloads. Mismanagement of compute resources is one of the largest contributors to Kubernetes expenses.
- Overprovisioning: Allocating more CPU or memory than workloads need leads to idle resources and inflated costs.
- Underutilization: Nodes operating consistently below capacity waste infrastructure, driving up costs unnecessarily.
- Scaling Challenges: Poorly configured autoscaling policies may cause overprovisioning (excess unused resources) or underprovisioning (insufficient resources causing performance degradation and downtime, leading to hidden costs like SLA penalties or lost revenue).
Storage costs
Persistent storage supports Kubernetes workloads by maintaining data integrity and availability across clusters. However, storage mismanagement can quickly escalate costs.
- Unattached Volumes: Storage volumes left behind after workloads are deleted continue to incur charges unless removed.
- Over-Provisioned Storage: Assigning excessive storage capacity to applications results in underutilized resources.
- High-Cost Storage Classes: Premium storage tiers like SSDs may exceed the performance requirements of non-critical workloads, unnecessarily increasing costs.
Network expenses
Kubernetes clusters generate significant network traffic as nodes, pods, and services communicate both internally and externally. Without careful architecture planning and cost monitoring, network expenses can escalate unexpectedly.
- Cross-Zone Data Transfers: Transferring data between availability zones (AZs) incurs additional costs on most cloud platforms. Unlike intra-zone traffic (typically free), inter-zone communication is metered separately and can significantly impact costs in high-traffic environments. Using single-zone architectures when feasible or configuring services to minimize cross-AZ data movement can help reduce unnecessary transfer fees.
- East-West vs. North-South Traffic: Kubernetes clusters generate two types of traffic:
- East-West (Internal): Communication between services within the cluster, such as microservices communicating across nodes or availability zones. If improperly configured, this traffic can route inefficiently, leading to unexpected costs.
- North-South (External): Traffic entering or leaving the cluster (e.g., API requests from users, data sent to external services). External traffic (especially across cloud providers) tends to be the most expensive.
- Ingress and Egress Costs: Outbound traffic (egress) from Kubernetes clusters incurs significant fees, particularly in multi-cloud or hybrid environments. Traffic within the same provider is generally cheaper, but data sent to external networks (e.g., third-party APIs, another cloud provider, or the public internet) is billed at higher rates. Optimizing data transfer strategies—such as using caching, compression, and cloud-native networking tools like service meshes—can help mitigate costs.
Best practices in Kubernetes cost optimization

Best practice #1: Right-size your Kubernetes resources
Right-sizing Kubernetes resources is one of the most effective ways to control compute costs while maintaining performance. Misconfigurations at both the node level (infrastructure) and pod level (workloads) can lead to cost inefficiencies, including overprovisioning (idle, wasted resources) or underprovisioning (performance degradation and downtime). A two-pronged approach—optimizing both nodes and workloads—ensures cost efficiency without sacrificing application performance.
Right-sizing Kubernetes nodes (infrastructure-level optimization)
Nodes serve as the foundation of a Kubernetes cluster, providing the CPU and memory that pods consume. Selecting the right instance types is essential to balancing performance and cost. Using overly large nodes for small workloads wastes resources, while nodes that are too small can result in fragmented capacity and scheduling inefficiencies.
To keep infrastructure lean, Kubernetes offers native autoscaling tools:
- Cluster Autoscaler adjusts the number of nodes dynamically based on pending workloads, ensuring efficient scaling to match demand fluctuations.
- Karpenter dynamically provisions nodes, selecting the most cost-efficient instance types and regions in real time to reduce cloud spend.
Monitoring node utilization with commands such as kubectl top nodes, along with tools like Prometheus or Grafana, helps identify inefficiencies, ensuring that clusters are neither over-provisioned nor running with excessive idle capacity.
Right-sizing Kubernetes pods (workload-level optimization)
Even with well-configured nodes, inefficient workload allocation can lead to resource waste. Kubernetes provides resource requests and limits to control how much CPU and memory each pod consumes.
- Requests define the minimum resources a pod needs to function.
- Limits cap the maximum it can use.
Misconfigurations in these settings can either lead to over-requesting, which wastes capacity, or under-requesting, which can degrade application performance.
Rather than relying on manual adjustments, AI-driven platforms like StormForge analyze workload behavior and dynamically recommend the optimal resource requests and limits for each application. By continuously refining these configurations, StormForge ensures workloads use only what they need—eliminating unnecessary waste while maintaining performance.
Regular monitoring is essential to maintaining efficient resource allocation. Using kubectl top pods, Prometheus, or Grafana, teams can track trends in resource consumption and make informed adjustments over time. Identifying workloads that consistently over-request or under-request resources provides opportunities for cost savings without impacting stability.
Best practice #2: Scale your clusters effectively
Scaling is one of Kubernetes’ most powerful features, playing a central role in Kubernetes cost optimization by dynamically adjusting resources to match workload demands. When implemented correctly, scaling ensures that applications maintain performance without over-allocating resources or incurring unnecessary costs. However, poorly configured scaling policies can lead to resource contention, inflated expenses, or underperformance. To achieve cost efficiency and operational agility, teams must leverage Kubernetes’ scaling tools, implement resource-based policies, and integrate predictive insights.
Use Kubernetes autoscaling tools
Kubernetes provides native autoscaling mechanisms that dynamically adjust resources in response real-time workload demands:
- Horizontal Pod Autoscaler (HPA) adjusts the number of pod replicas based on CPU or memory utilization, scaling workloads up or down as traffic fluctuates.
- Vertical Pod Autoscaler (VPA) Analyzes historical resource usage and automatically adjusts CPU and memory requests to prevent overprovisioning or resource contention.
- Cluster Autoscaler and Karpenter work at the infrastructure level, ensuring workloads run on the most cost-effective node configurations while avoiding idle capacity.
However, while these tools dynamically adjust resources, they typically react to workload spikes rather than proactively anticipating changes.
Integrate predictive insights for smarter scaling
Predictive analytics strengthens scaling strategies by forecasting workload fluctuations and proactively adjusting resources before bottlenecks occur. Platforms like StormForge analyze historical trends and workload patterns, enabling teams to forecast demand and configure scaling policies proactively. For example, if traffic increases regularly during specific hours, predictive insights can help teams pre-scale resources to avoid service degradation or over-allocation.
CloudBolt complements this approach by overlaying financial data onto scaling decisions. This integration ensures that resource adjustments support both operational goals and cost-efficiency targets, providing a holistic strategy for managing Kubernetes workloads.
Best practice #3: Optimize storage use
Storage plays a critical role in Kubernetes cost optimization, ensuring data persistence while preventing excessive storage provisioning and unnecessary costs. However, mismanaged storage can quickly inflate costs. Common pitfalls include unattached volumes, over-provisioned resources, and reliance on premium storage tiers for non-critical workloads. Implementing proactive storage management strategies helps organizations reduce expenses while maintaining performance and reliability.
Leverage Kubernetes storage features
Kubernetes provides flexible storage management tools to help allocate resources efficiently. Persistent Volume Claims (PVCs) allow users to dynamically provision storage based on workload requirements. However, Kubernetes does not natively enforce storage efficiency—administrators must configure appropriate limits, quotas, and auto-scaling policies to prevent excessive allocation.
Storage classes enable teams to define different storage tiers, balancing performance and cost. High-performance SSDs should be reserved for latency-sensitive applications, while standard storage tiers are better suited for non-critical workloads like backups or log retention. Some cloud providers also offer auto-scaling storage options, which can dynamically expand capacity as workload demands grow. However, not all storage backends support automatic volume resizing, and administrators must verify compatibility with their chosen storage provider (e.g., AWS EBS, Azure Disk, GCP PD).
Clean up orphaned and unattached volumes
One of the most common sources of wasted costs in Kubernetes environments is unattached volumes—storage resources that remain active after workloads are deleted. These orphaned volumes continue to incur charges unless manually cleaned up.
Administrators can use kubectl get pv to audit persistent volumes and identify unused storage. Cloud providers often provide additional cost visibility tools, such as AWS Cost Explorer, GCP Storage Insights, or Azure Cost Management, which help track lingering storage costs. Automated policies can further streamline cleanup efforts by flagging and removing orphaned volumes.
Optimize storage classes for cost efficiency
Aligning storage classes with workload needs is critical for managing costs effectively. Premium storage tiers offer high performance but come at a significant cost, making them best suited for mission-critical applications. Non-critical workloads, such as backups or infrequently accessed logs, should be stored in lower-cost storage tiers.
For multi-tiered environments, automated storage policies can improve efficiency by dynamically shifting infrequently accessed data to lower-cost archival storage, such as AWS S3 Infrequent Access or Google Cloud Nearline. Lifecycle management policies can further reduce costs by setting expiration rules for unused data.
Monitor and adjust storage usage continuously
Storage optimization is an ongoing process, requiring regular monitoring to ensure allocations remain aligned with workload demands. The same observability tools used for cluster performance—such as Prometheus, AWS CloudWatch, Azure Monitor, and GCP Operations Suite—also provide visibility into storage consumption trends.
To take this further, platforms like CloudBolt integrate cost insights with usage metrics, providing real-time recommendations for optimizing storage costs. By identifying underutilized volumes or recommending reclassification of workloads to more cost-effective storage tiers, organizations can keep storage spend under control while maintaining availability.
Best practice #4: Leverage monitoring and logging
Monitoring and logging play a vital role in Kubernetes cost optimization, helping teams balance visibility with cost efficiency to prevent over-collection of metrics and unnecessary storage expenses. Effective monitoring provides actionable insights into cluster health and resource usage, while comprehensive logging enables teams to troubleshoot issues and optimize operations. Together, they form the backbone of a proactive Kubernetes cost optimization strategy.
Monitor cluster health and resource utilization
A holistic monitoring strategy helps teams track resource consumption and performance trends. Prometheus and Grafana remain essential for real-time observability, providing detailed insights into CPU, memory, and network usage. Prometheus efficiently collects and stores time-series data, while Grafana translates these metrics into intuitive, customizable dashboards for better visibility.
For organizations leveraging cloud-native monitoring, AWS CloudWatch, Azure Monitor, and Google Cloud Operations Suite integrate natively with their respective platforms, offering automated alerts, event-driven responses, and performance tracking tailored to Kubernetes workloads.
However, monitoring costs can escalate quickly across all cloud providers—particularly when handling high-frequency metrics, large log volumes, or long retention periods. These services charge based on data ingestion, storage, and retrieval, meaning excessive logs and metrics can lead to unexpected cost spikes if left unmanaged.
To mitigate costs:
- Filter and route logs efficiently: Instead of ingesting all logs into a premium monitoring service, use Fluentd or Vector to filter data before sending it to a lower-cost storage solution (e.g., Amazon S3, Azure Blob Storage, or Google Cloud Storage).
- Adjust log retention policies: Shorten retention periods for non-critical logs and move archived logs to infrequent access tiers.
- Consider open-source monitoring alternatives: Self-hosted solutions like Loki (Grafana Labs) offer cost-effective log storage without cloud provider fees.
Leverage logging for proactive troubleshooting
Logging provides a historical record of system events and errors, allowing teams to quickly diagnose performance issues. Centralized solutions like the ELK Stack (Elasticsearch, Logstash, Kibana) and Fluentd aggregate logs from across nodes and pods, making them easier to search and analyze.
Cloud-based logging tools, such as AWS CloudWatch Logs and Google Cloud Logging, offer powerful filtering and search capabilities but can quickly become costly when handling high-volume data. To optimize logging costs:
- Limit log verbosity for non-critical workloads: Debug-level logs should only be enabled when troubleshooting, not as a default setting.
- Use structured logging with filtering: Fluentd allows log filtering before ingestion, preventing unnecessary data from being stored.
- Consider hybrid storage: Sending only high-priority logs to CloudWatch while archiving low-priority logs to Amazon S3 or a self-hosted ELK stack can reduce costs.
Automate monitoring and logging for greater efficiency
Automation reduces manual overhead in monitoring and logging while improving response times. Prometheus and Grafana streamline metric collection and alerting, while Fluentd and the ELK Stack handle log aggregation and analysis.
StormForge’s machine learning capabilities take this further by proactively analyzing workload performance and recommending optimizations. Unlike traditional integrations that rely on external monitoring data, StormForge collects its own workload metrics, ensuring recommendations are directly based on real Kubernetes behavior.
By automating inefficiency detection and workload rightsizing, StormForge enables continuous, data-driven optimization. Automated reporting further simplifies performance tracking, giving teams a real-time view of efficiency trends over time without manual intervention.
Best practice #5: Leverage quotas within namespaces
Namespaces in Kubernetes serve as logical partitions for organizing resources across teams, projects, or environments. However, when resources are not managed carefully within these partitions, imbalances can occur. Applying quotas to namespaces enables effective resource allocation, ensuring that workloads operate efficiently while preventing resource contention or runaway costs.
Apply resource quotas strategically
Quotas define limits for CPU, memory, and storage consumption at the namespace level, protecting against resource starvation and runaway workloads. By setting these boundaries, organizations can safeguard mission-critical workloads while allowing flexibility for less critical tasks. For instance, in environments shared by development, testing, and production teams, quotas can prevent experimental workloads from disrupting the stability or costs of production operations.
When combined with pod-level limits and requests, quotas offer an additional layer of granularity. Limits specify the maximum resources a pod can consume, while requests define the minimum it requires to run effectively. Together, these configurations ensure balanced resource allocation, aligning with workload demands without over- or under-provisioning. For example, setting memory limits for high-performance applications prevents them from monopolizing namespace resources while allowing other workloads to operate seamlessly.
Automate quota enforcement for consistency
Automation ensures consistent quota enforcement and reduces the administrative overhead of manual adjustments. By leveraging Kubernetes’ native policies alongside AI-driven platforms, teams can dynamically modify quotas in response to real-time usage patterns.
StormForge automates the reallocation of unused resources, shifting capacity from low-demand namespaces to high-priority workloads. Automated alerts notify administrators when namespaces approach their limits, allowing proactive adjustments before disruptions occur.
Integrating quota automation with broader cost management practices keeps resource allocations efficient and aligned with organizational objectives, strengthening both operational performance and financial control.
Best practice #6: Leverage cloud-native cloud savings
For Kubernetes clusters running in the cloud, cloud provider cost-saving programs offer substantial opportunities to reduce expenses while maintaining performance. Spot instances, reserved instances, and volume discounts enable organizations to optimize resource allocation for different workload types, balancing scalability, reliability, and cost efficiency.
Utilize spot instances for non-critical workloads
Spot instances provide access to unused cloud capacity at deeply discounted rates, making them ideal for non-critical, fault-tolerant workloads such as batch processing, testing, and data analysis. AWS, Azure, and Google Cloud offer spot instances that can reduce compute costs by 70-90% compared to on-demand pricing.
To maintain workload stability when using spot instances, Kubernetes’ autoscaling mechanisms can dynamically adjust resources. Cluster Autoscaler ensures that workloads are rescheduled to available capacity when spot instances are reclaimed, while Karpenter optimizes node provisioning in real time to maximize cost efficiency and performance.
Commit to reserved instances for predictable workloads
For workloads with stable, predictable demands, reserved instances (RIs) offer substantial cost savings in exchange for long-term usage commitments (typically one- or three-year terms). By locking in discounted pricing, organizations can lower costs for production environments and steady-state applications that require consistent resource availability.
However, choosing the right RI configuration is critical to maximizing savings. Teams should evaluate:
- 1-year vs. 3-year commitments: Longer commitments offer great discounts but reduce flexibility.
- Standard vs. Convertible RIs: Standard RIs lock in specific instance types, while convertible RIs allow adjustments to instance family, OS, or region.
- Partial vs. Full Upfront Payment: Some cloud providers offer deeper discounts for prepaying, while others allow monthly payments at slightly higher rates.
While RIs can significantly reduce costs, mismanagement can lead to unnecessary expenses. Overcommitting can result in unused reserved capacity, while failing to properly allocate workloads to RIs may default them to on-demand pricing, negating potential savings. Regular monitoring of RI utilization helps ensure businesses get the most value from their reserved resources.
Leverage volume discounts for high-usage workloads
Most cloud providers offer tiered pricing models, where increased usage results in lower per-unit costs. Organizations can take advantage of these discounts by optimizing resource allocation across storage and compute:
- Storage Discounts: Consolidating high-capacity storage for data archiving or long-term backups can lower costs by meeting provider-specific tiered pricing thresholds (e.g., AWS S3 Infrequent Access, Google Cloud Nearline).
- Compute Savings Plans: Programs like AWS Savings Plans and Azure Reserved VM Instances offer flexibility in instance types and commitment terms, providing significant cost reductions for sustained usage.
- Networking Discounts: Some cloud providers offer volume-based discounts on outbound data transfer costs. Aggregating network-heavy workloads in the same region or leveraging private links can reduce expenses.
- Commitment-Based Discounts: Organizations with predictable workload needs can benefit from negotiated enterprise agreements with cloud providers, securing custom pricing discounts based on projected consumption.
By strategically consolidating workloads, analyzing historical usage patterns, and adjusting resource commitments, teams can maximize cloud savings while maintaining flexibility.
Augmented FinOps: The key to optimizing Kubernetes costs
As Kubernetes environments grow in complexity, implementing best practices alone may not be enough to achieve sustainable cost efficiency. This is where Augmented FinOps takes the lead, transforming manual, time-consuming processes into automated, continuous optimization workflows. By enhancing your Kubernetes cost management efforts, Augmented FinOps ensures that every resource in your cluster operates at peak efficiency—both financially and operationally.
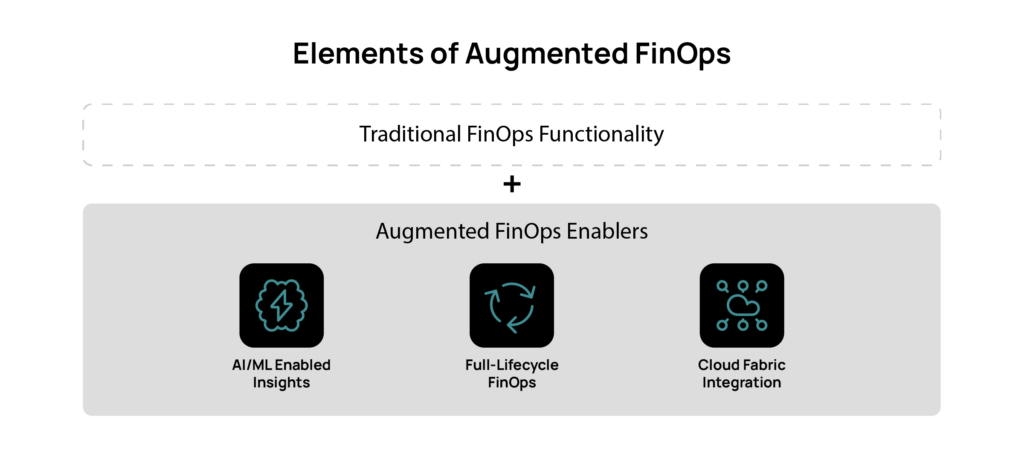
Why Augmented FinOps?
Augmented FinOps bridges the gap between operational efficiency and financial accountability, offering AI-driven automation that optimizes cloud resource management while ensuring accurate financial governance. The integrated approach enables teams to:
- Automate Cost-Aware Scaling: Machine learning continuously optimizes resource allocation, delivering documented savings of up to 50% through intelligent rightsizing and automated resource management.
- Enable Precise Cost Allocation: Teams can implement granular showback and chargeback mechanisms based on real container-level performance data, ensuring accurate, transparent, and uncontested cost distribution across teams.
- Unify Monitoring with Real-Time Optimization: A single-pane-of-glass view combines financial data with operational metrics, reducing insight-to-action time from weeks to minutes through automated optimization workflows.
How Augmented FinOps enhances Kubernetes optimization
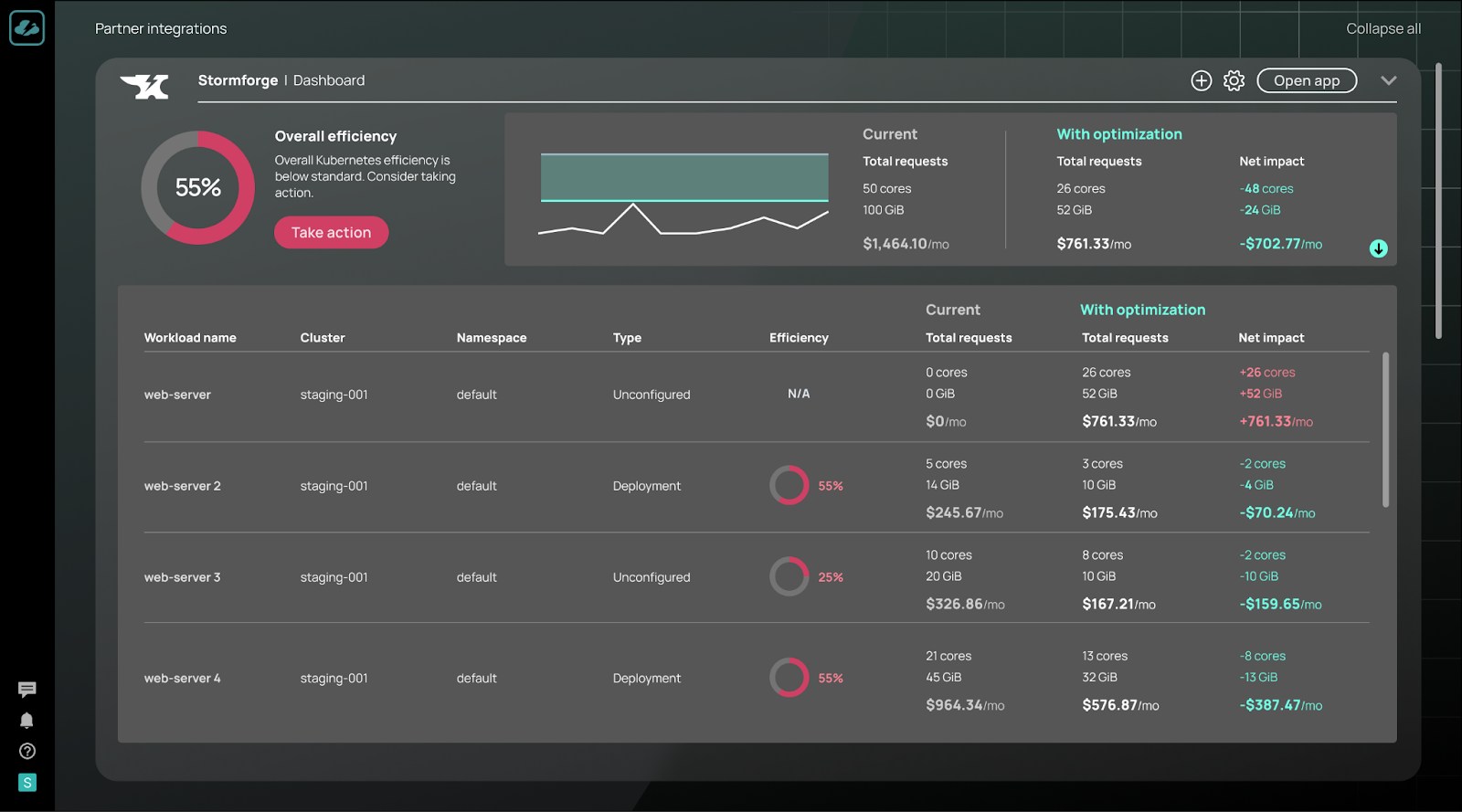
By integrating with Kubernetes’ native capabilities, Augmented FinOps automates Kubernetes cost optimization at the container level, turning manual, time-consuming cost management processes into continuous, data-driven workflows:
- Continuous Monitoring: The system identifies inefficiencies and optimization opportunities in real time, eliminating manual intervention for workload rightsizing.
- Automated Execution: Augmented FinOps not only provides cost-saving recommendations but also automates resource adjustments using machine learning insights and predefined policies.
- Performance-Aware Optimization: ML-driven algorithms balance cost savings with performance requirements, ensuring efficiency without compromising application reliability.
For example, if resource allocation mismatches are detected in a staging environment, Augmented FinOps automatically rightsizes container resources and optimizes workload configurations. These adjustments are made in real-time, ensuring workloads remain cost-efficient while meeting performance standards—without requiring manual intervention.
Ready to optimize your Kubernetes costs?
Augmented FinOps moves Kubernetes cost optimization beyond reactive oversight into an automated, continuous optimization process. Whether you’re optimizing existing clusters or preparing for scaling new workloads, Augmented FinOps ensures Kubernetes environments remain agile, efficient, and cost-effective while delivering proven cost savings.
Discover the impact of Augmented FinOps firsthand. Schedule a demo today to see how CloudBolt and StormForge bring AI-driven, automated cost optimization to Kubernetes workloads.
FAQs for Kubernetes cost optimization
How does Kubernetes automatically optimize for cost?
Kubernetes reduces cloud waste through autoscaling, workload scheduling, and resource quotas, ensuring resources scale with demand rather than sitting idle. Key optimizations include:
- Dynamic scaling: Pods and nodes scale up or down based on real-time usage.
- Resource efficiency: Workloads are scheduled to maximize utilization without overprovisioning.
- Quota enforcement: Prevents overuse by setting CPU, memory, and storage limits per namespace.
By combining these mechanisms, Kubernetes cost optimization becomes an automated, built-in process that aligns infrastructure with operational and financial efficiency.
How much does it cost to run a Kubernetes cluster?
Kubernetes costs vary based on cloud provider, workload type, and optimization strategies. Broad estimates include:
- Light workloads (small development or testing clusters): $100–$500 per month
- Standard production workloads (web applications, APIs, business applications): $500–$5,000 per month
- Enterprise-scale workloads (big data, high-traffic services): Tens of thousands per month
Cost-saving strategies such as spot instances, reserved instances, autoscaling, and workload rightsizing can significantly reduce expenses.
What are the hidden costs of running Kubernetes?
Even with proper provisioning, unexpected expenses can arise in Kubernetes environments. Common hidden costs include:
- Inefficient resource allocation – Over-requested CPU and memory, idle nodes, and underutilized resources.
- Data transfer and network egress fees – Costs from cross-zone communication and external API calls.
- Excessive log ingestion – High-frequency logs stored in expensive storage tiers.
Regularly auditing orphaned volumes, unused instances, and inefficient network traffic, along with budget alerts and cost monitoring, can help mitigate these hidden costs.
Can Kubernetes be integrated with FinOps frameworks?
Yes, Kubernetes aligns well with FinOps principles by improving cost visibility, financial accountability, and automation. Teams can track and allocate costs more precisely by tagging workloads, while automation ensures that scaling and rightsizing decisions are based on real-time data. This integration enables organizations to optimize cloud spending while maintaining transparency across finance, engineering, and operations teams.
Is Kubernetes cost-efficient for small businesses?
Kubernetes can be a cost-effective choice for small businesses that need scalability, flexibility, and multi-cloud capabilities, particularly when using managed services like EKS, GKE, or AKS to reduce maintenance overhead. However, for businesses with static workloads or minimal cloud usage, traditional VMs or serverless computing may be more cost-efficient. Small teams should weigh Kubernetes’ benefits against its operational complexity and consider starting with a managed Kubernetes service to minimize costs and simplify management.
Related Blogs

The End of Manual Optimization: Why We Acquired StormForge
Today is a big day for CloudBolt—we’ve officially announced our acquisition of StormForge. This marks a major milestone for us…
