Using AWS, you can set up and deploy all kinds of services within minutes–everything from virtual machines and containers, to file storage, to databases, and even a programming code function. While deploying AWS services can be easy, sizing them can be challenging.
In fact, it’s hard to anticipate the amount of resources your new project might require without historical data on a similar application, run with a similar code stack, receiving similar levels of user activity, during peak usage hours. And because of so much unknown, it’s far safer to overestimate your resource needs than it is to risk application stability by trying to start off lean. But there is something you can do to dial in those resources soon after deploying them.
In this article, we’ll take a look at the most common AWS sizing tools for resource optimization, broken down by their different approaches, so you can start reducing your overall bill.
1. Sizing by Recommendations
Trusted Advisor is an AWS sizing tool that provides resource recommendations across five categories: cost optimization, performance, security, fault-tolerance, and service limits. These recommendations are powered by checks (up to 115 in total) that run in real-time across each category.
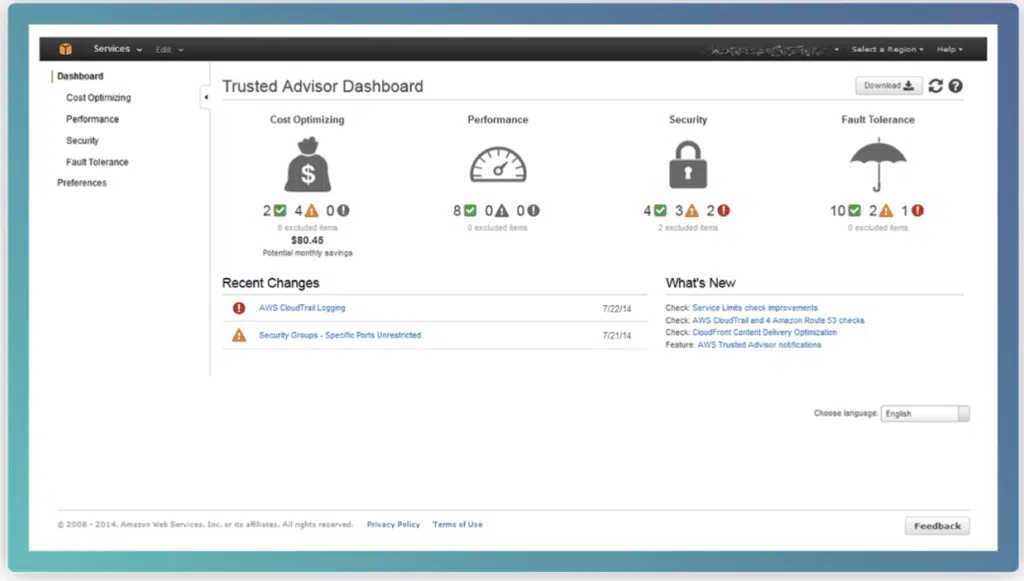
These checks can save you money by automatically:
- Identifying unused resources
- Identifying idle resources
- Recommending Savings Plan purchases
- Checking for over- or under- used instances
- Checking reservation contract expirations
Trusted Advisor also supports email notifications that trigger when a check’s status changes. You can use ongoing real-time checks and email notifications as a great way to trigger automating your scripted AWS sizing tasks.
This service offers two basic checks for free. For full access to all of Trust Adviser’s checks, you must have the business or enterprise AWS support tier.
See the best multi-cloud management solution on the market, and when you book & attend your CloudBolt demo we’ll send you a $75 Amazon Gift Card.
2. Sizing by Historical Workloads
The Compute Optimizer is a tool that provides AWS sizing recommendations for your inventory of Amazon EC2 instances. This tool analyzes historical resource utilization data (via CloudWatch) to create optimal resource recommendations for maintaining similar workloads. These recommendations commonly consist of switching instance sizes or instance types, but can also include Auto Scaling Group (ASG) and EBS volume recommendations.
The Compute Optimizer’s dashboard provides a visual representation of your total under-provisioned, over-provisioned, and optimized resources so that you can quickly gauge the overall efficiency of your inventory by each resource type.
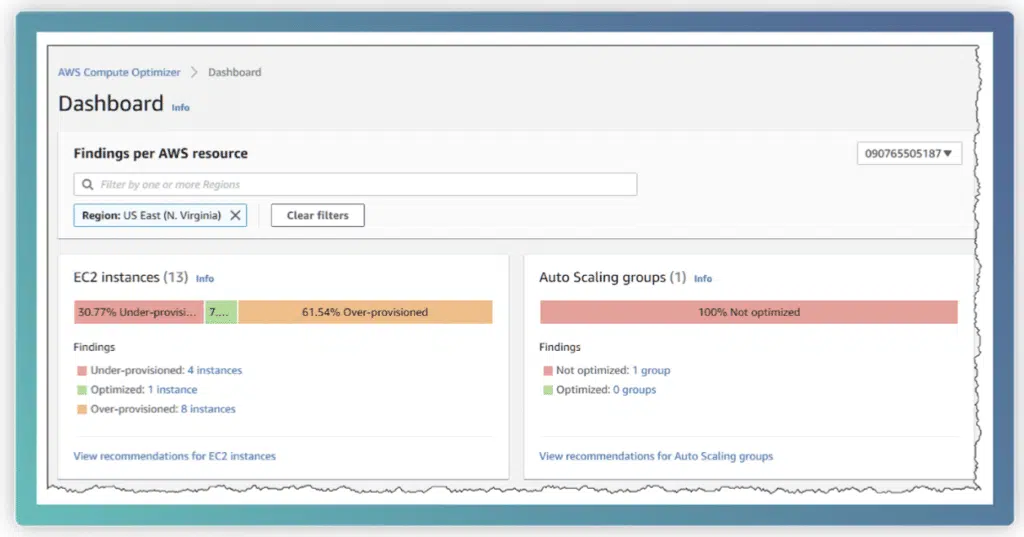
When reviewing a recommendation, you can check the forecasted CPU and Memory utilization for that recommended instance type. This is great for checking if a recommendation’s resource utilization is at or below an acceptable threshold (e.g., your risk tolerance for spikes in CPU utilization of a fully utilized instance).
You can save money with the AWS Compute Optimizer by analyzing any of the following workload types:
- CPU-intensive workloads
- Network-intensive workloads
- IO-intensive workloads
- Memory-intensive workloads
To get sizing recommendations based on memory utilization and other operating-system level metrics, you must install a CloudWatch agent to your EC2s.
For those of you who prefer using the AWS CLI, you can review recommendations as JSON. Here is an example of what that would look like:
$ aws compute-optimizer get-ec2-instance-recommendations --instance-arns
arn:aws:ec2:us-east-1:012345678912:instance/i-0218a45abd8b53658
{
"instanceRecommendations": [
{
"instanceArn": "arn:aws:ec2:us-east-1:012345678912:instance/i-0218a45abd8b53658",
"accountId": "012345678912",
"currentInstanceType": "m5.xlarge",
"finding": "OVER_PROVISIONED",
"utilizationMetrics": [
{
"name": "CPU",
"statistic": "MAXIMUM",
"value": 2.0
}
],
"lookBackPeriodInDays": 14.0,
"recommendationOptions": [
{
"instanceType": "r5.large",
"projectedUtilizationMetrics": [
{
"name": "CPU",
"statistic": "MAXIMUM",
"value": 3.2
}
],
"performanceRisk": 1.0,
"rank": 1
},
{
"instanceType": "t3.xlarge",
"projectedUtilizationMetrics": [
{
"name": "CPU",
"statistic": "MAXIMUM",
"value": 2.0
}
],
"performanceRisk": 3.0,
"rank": 2
},
{
"instanceType": "m5.xlarge",
"projectedUtilizationMetrics": [
{
"name": "CPU",
"statistic": "MAXIMUM",
"value": 2.0
}
],
"performanceRisk": 1.0,
"rank": 3
}
],
"recommendationSources": [
{
"recommendationSourceArn": "arn:aws:ec2:us-east-1:012345678912:instance/
i-0218a45abd8b53658",
"recommendationSourceType": "Ec2Instance"
}
],
"lastRefreshTimestamp": 1575006953.102
}
],
"errors": []
}
Overall, the AWS Compute Optimizer teaches users to be more aware of over-provisioning and under-provisioning their resources, and conduct what-if analysis. This service is available for free. To get started, simply opt into the service from within your AWS Compute Optimizer Console.
|
Platform
|
Multi Cloud Integrations
|
Cost Management
|
Security & Compliance
|
Provisioning Automation
|
Automated Discovery
|
Infrastructure Testing
|
Collaborative Exchange
|
|---|---|---|---|---|---|---|---|
|
CloudHealth
|
✔
|
✔
|
✔
|
||||
|
Morpheus
|
✔
|
✔
|
✔
|
||||
|
CloudBolt
|
✔
|
✔
|
✔
|
✔
|
✔
|
✔
|
✔
|
3. Sizing by Future Workload Estimations
The EC2 Predictive Scaling is a sizing feature of ASGs that allows you to scale your fleet using anticipated workload requirements. Predictive scaling works by measuring daily and weekly traffic behavior to determine when (on average) usage is expected to change, by how much, and for how long.
Predictive Scaling policies require at least one day of historical data to begin making future predictions. After setup, the policy’s model evaluates activity every 24 hours to forecast EC2 usages for the following 48 hours. It then schedules these changes as scaling actions, with the goal of maintaining utilization at the target level specified in the scaling strategy.
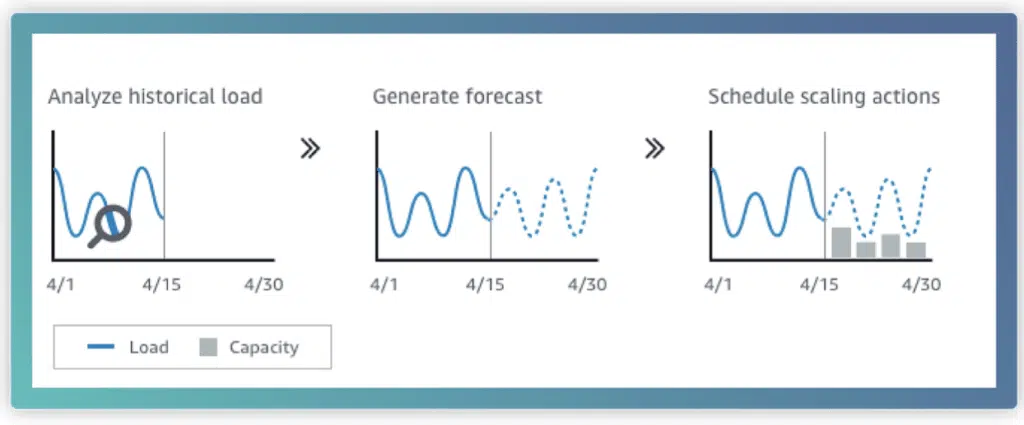
You can use predictive scaling in conjunction with dynamic scaling strategies. This means that you can provision the node count in your ASG based on predicted requirements according to historical weekly and daily patterns, however for additional confidence, you can also account for the changing values of real-time metrics (such as CPU) to adjust your node count to accommodate an unexpected jump in workload. Using a predictive scaling model can trim down time spent running larger instances. And since EC2s are metered per-second and rollup into instance-hours, you can significantly lower your bill through this one AWS sizing technique alone.
4. Sizing by Data Access Patterns
S3 Intelligent-Tiering is a class of S3 storage that automatically shuttles data between a series of frequently accessed and infrequently accessed tiers as a means of providing cost savings on storage.
Here’s how each tier works:
| Tier | Days Since Last Retrieval | Pricing |
|---|---|---|
| Frequently Access | 0-30 days | Standard S3. |
| Infrequently Access | 31-90 days | Standard S3 – Infrequent Access |
| Archive Access | 91-180 days | S3 Glacier |
| Deep Archive Access | > 180 days | S3 Glacier Deep Archive |
The data retrieval process for S3 Intelligent-Tiering is not subject to fees, however you should expect slower retrieval times for Archive Access (3-5 hours) and Deep Archive Access (12 hours).
To enable this AWS sizing feature, simply navigate to your S3 bucket’s properties and create a configuration for S3 Intelligent-Tiering. Here, you can specify which objects should be considered for tiering through a variety of filters and tag selections.
5. Sizing by Delegation
AWS Fargate is a serverless compute engine for containers that automatically launches and scales the underlying EC2 cluster to match the required workload capacity. The idea is simply to delegate the management of nodes, PODs and clusters to AWS, and only be responsible for launching containers. Keep in mind that you are still responsible for selecting a size for your container, and you would pay a bit more for the convenience, however, you no longer have to worry about provisioning nodes into a cluster.
Fargate offers a pay-as-you-go model, with pricing options such as Spot, On-Demand, and Reserved — similar to those available for Amazon EC2 instances.
6. Sizing by CPU Spikes
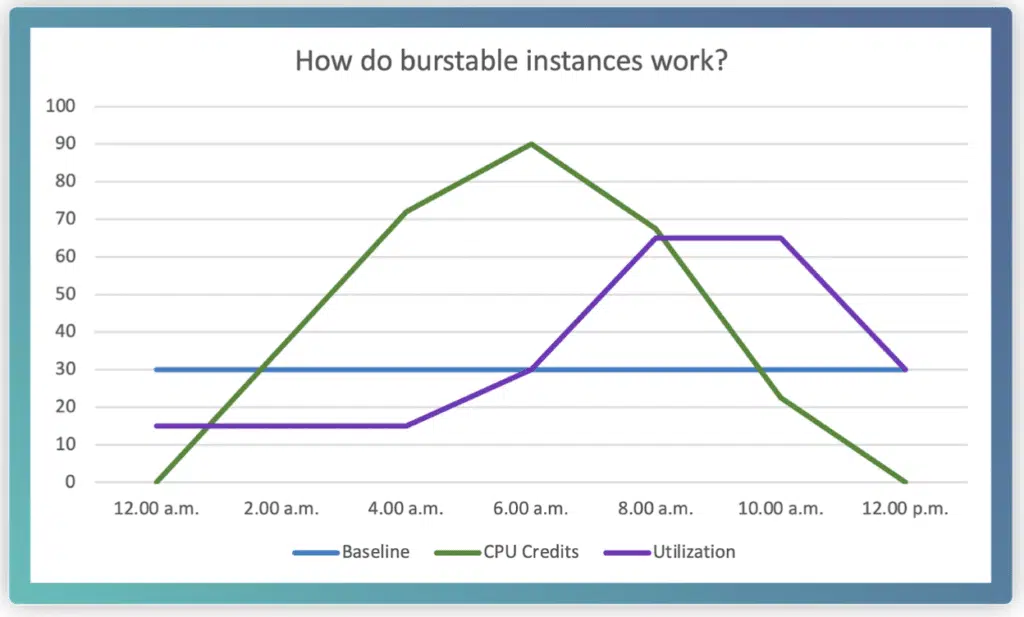
Burstable Performance Instances are instances that typically operate on a baseline-level of CPU performance, but when workload demands increase, they can temporarily burst their performance to meet demand. This burst mechanism is controlled by CPU credits that accrue hourly over time (at a rate varying by instance size) when the instance is performing at a baseline level.
T2, T3, T3a, and T4g are the only instance families that support the Burstable Performance feature. You can use Burstable Performance Instances for On-Demand, Spot, and Reserved Instances purchasing options.
Credits are consumed at the following rates:
- 100% Utilization of One vCPU: One minute
- 50% Utilization of One vCOU: Two minutes
- 25% Utilization of Two vCPUs: Two minutes
Credits accrued for an instance do not expire, however, there is a limit to how many credits an instance can hold.
This instance type suits general-purpose applications, such as microservices, small and medium-sized databases, interactive applications with low-latency, development, virtual desktops, stage environments, build, product prototypes, and code repositories.
AWS offers a neat feature known as “unlimited” which means that there is no limit to your CPU usage, however you are charged for it in the form of surplus credits. This helps if you have an important CPU-intensive workload that is unpredictable in nature. Remember that T3a and T4g are configured as “unlimited” by default which can unintentionally result in an ever-increasing bill.
While choosing the instance size, make sure that it passes the minimum memory requirements of the underlying operating system and applications. If the application has graphical users, then the operating system consumes significant memory and CPU resources — therefore, the instance size should be large enough for many use cases. Based on the memory and CPU growth requirements over time, scaling to a larger instance type will be required.

Only solution with automated discovery, testing, provisioning, security, and cost management

A `single pane`for infrastructure spanning on-premise, private cloud, and multiple public clouds

A comprehensive framework that extends your existing tool investments and fills the gaps
Conclusion
Although sizing your resources can be a challenge, there are several approaches you can take to make the task easier and less risky for your application stability. The delegation of sizing may be free in some cases (such as Intelligent S3), could cost you a premium for its convenience (such as Fargate), or can result in a surprise charge (such as T4g’s default unlimited burstable CPU). When used strategically, it can save you time and also money.
Related Blogs

The End of Manual Optimization: Why We Acquired StormForge
Today is a big day for CloudBolt—we’ve officially announced our acquisition of StormForge. This marks a major milestone for us…
